



主数据的辨识问题可以看作主数据元的辨识问题,可有公式为:
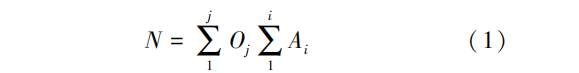
由式 (1) 可知 , 对于数据元的提取 , 应先分析系统中的对象 , 再从对象中分析属性 , 从而提取 出全部的数据元 N。
本文将 IDEF0 和 UML 建模方法结合起来 , 自顶向下对煤炭企业的业务进行全面分析 。本文所建立的煤炭企业主数据辨识方法如图 1 所示。
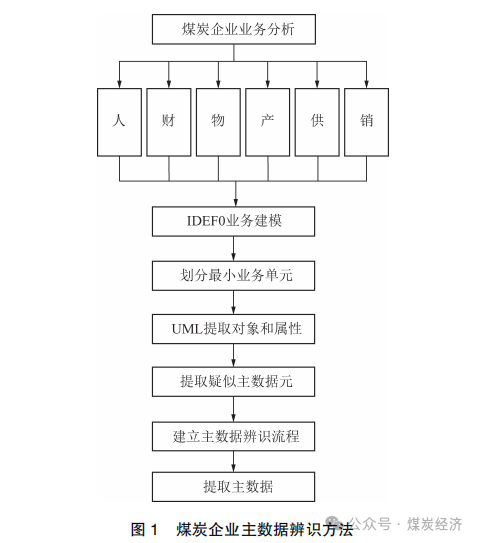
煤炭企业业务分析框架建立
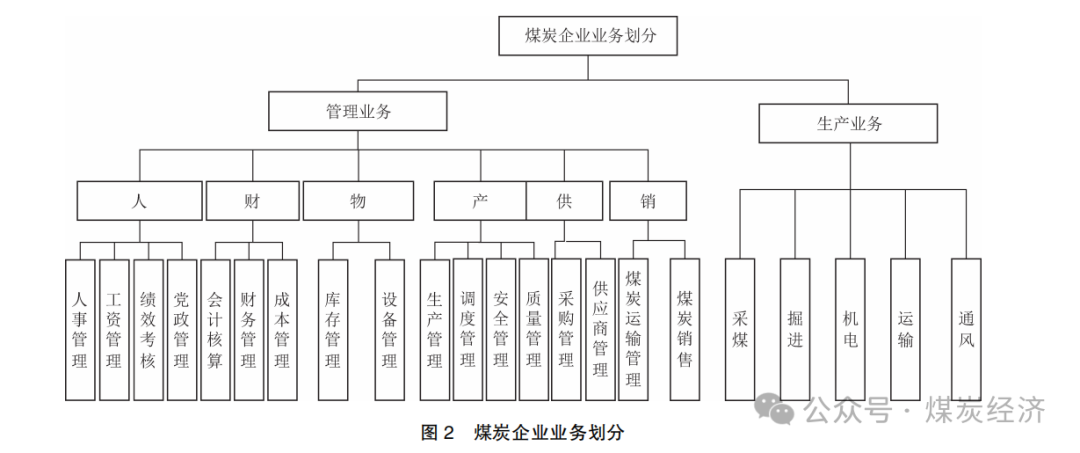
煤炭企业业务划分如图 2 所示 。根据对国有煤炭企业集团的详细调查分析 , 煤炭企业业务可以分为生产业务和管理业务两大类 。因为管理业务中的产是对生产业务进行管理 , 因此本文主要以管理业务划分分析框架。
基于IDEF0的煤炭企业
业务分析
以图 2 为分析框架 , 运用 IDEF0 方法对煤炭企业进行业务建模 , 将以上煤炭企业业务框架划分成为最小的业务单元 , 作为数据元提取的依据。
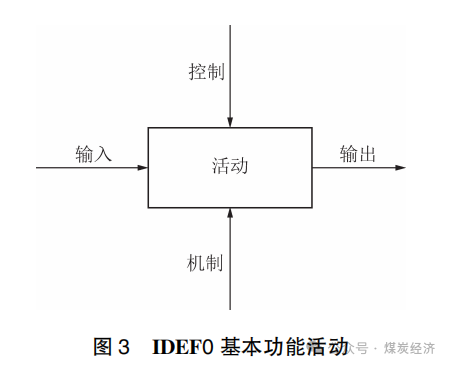
IDEF0 建模的主要元素是由盒子和箭头组成 , 如图 3 所示 , 方盒代表完成某种功能的活动 , 箭头表示活动所需或活动产生的真实信息或对象;IDEF0 基本功能活动由活动、控制、机制、输入、输出5个元素组成 , 控制是该活动执行的机制和条件 , 机制是执行活动的人或设备 。
以图 2 作为 IDEF0 的建模框架 , 根据图 4 , 运用 IDEF0 建模方法对各业务继续进行分解 , 直到将煤炭企业生产业务活动划分为最小的业务活动单元 。
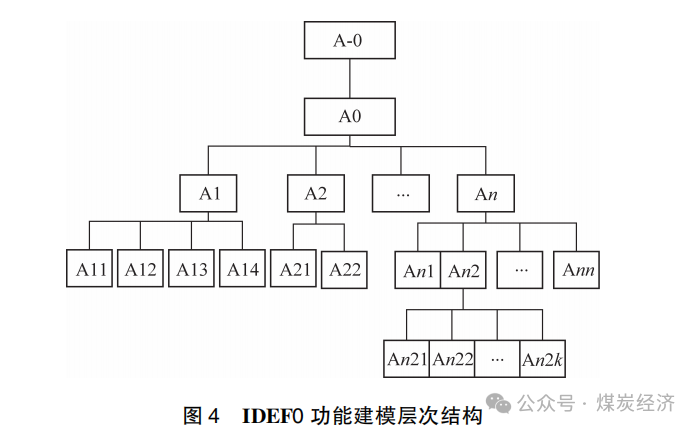
具体可分为以下几个步骤。
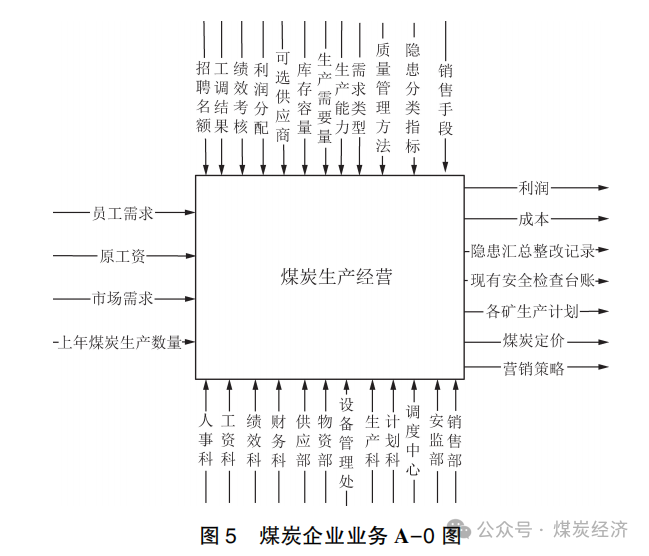
1) 根据煤炭企业管理业务的输入和输出 , 构建顶层图 A-0 图 , 如图 5 所示。
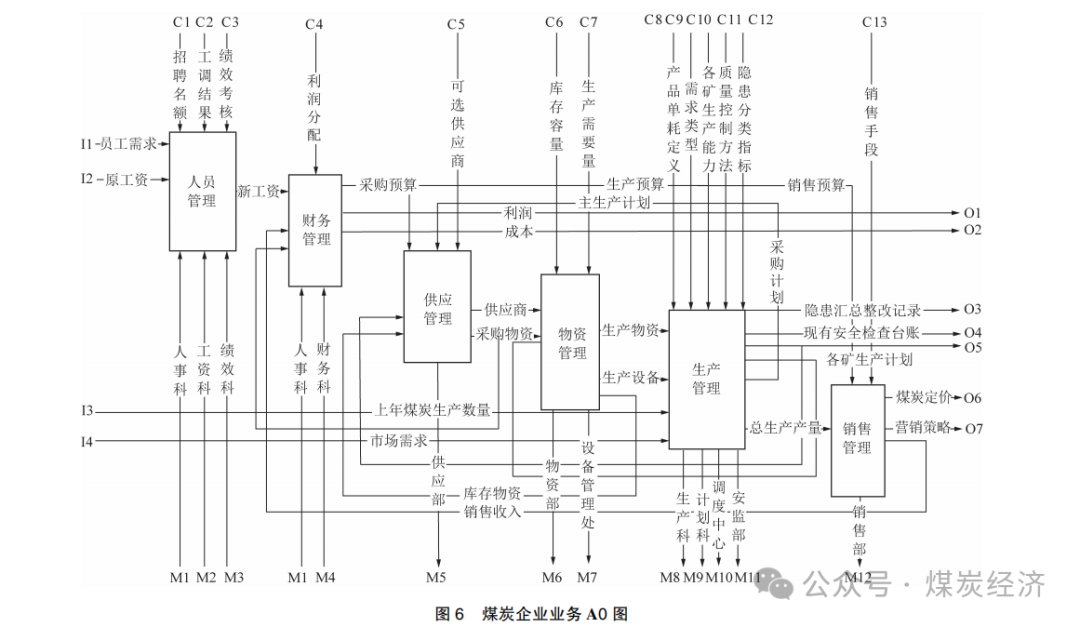
2) 根据图 2 , 运用 IDEF0 , 在 A-0 图的基础 上 , 构建煤炭企业 A0 图 , 将煤炭企业的业务划分为人员管理 、财务管理 、供应管理 、物资管理 、生产管理 、销售管理 6 个方面 , 如图 6 所示。
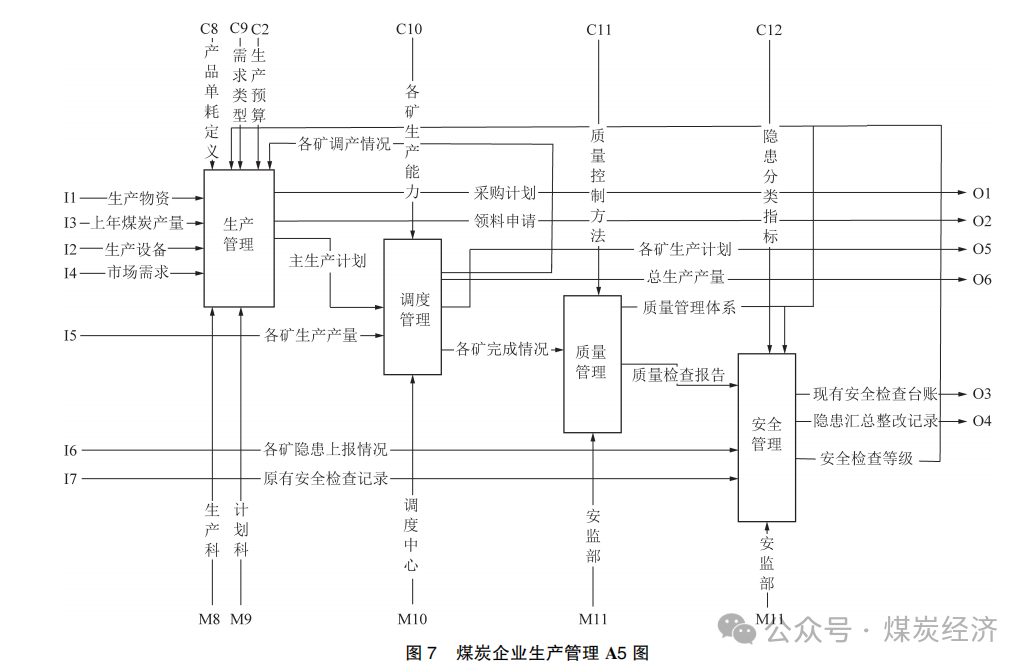
3) 根据图 6 对煤炭企业生产经营活动的划分 , 以生产管理业务为例 , 建立煤炭企业生产运作 A5 图 , 如图 7 所示 , 将生产管理业务划分成为生产管理 、调度管理 、质量管理和安全管理 4 部分。
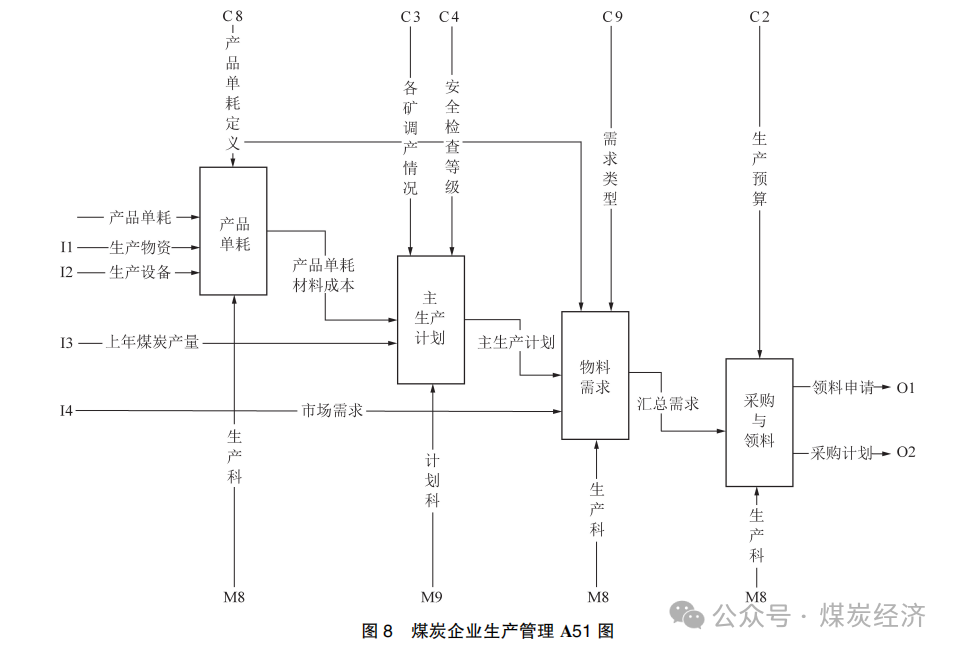
4) 在 A5 图的基础上,继续对生产管理业务进行划分,在生产管理、调度管理、质量管理、安全管理中 , 以生产管理为例 , 建立煤炭企业生产管理 A51图 , 如图 8 所示 , 将煤炭企业生产管理继续划分成为产品单耗、主生产计划、物料需求 、采购与领料 4 部分。
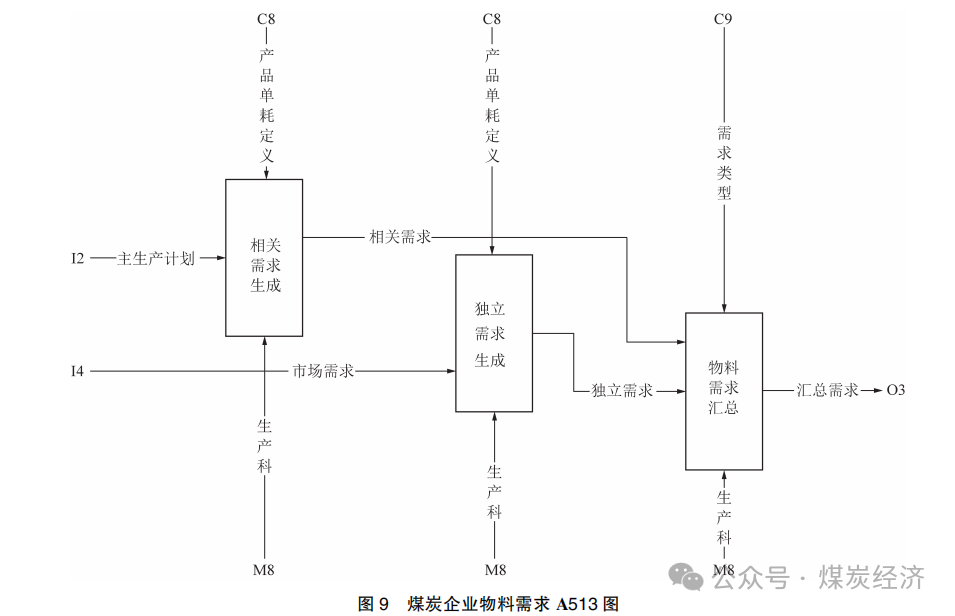
5) 在A51图的基础上,进一步细分生产管理业务,以物料需求为例,建立物料需求A513图 , 如图 9 所示 , 将物料需求划分成为相关需求生成、独立需求生成和物料需求汇总 3 部分。
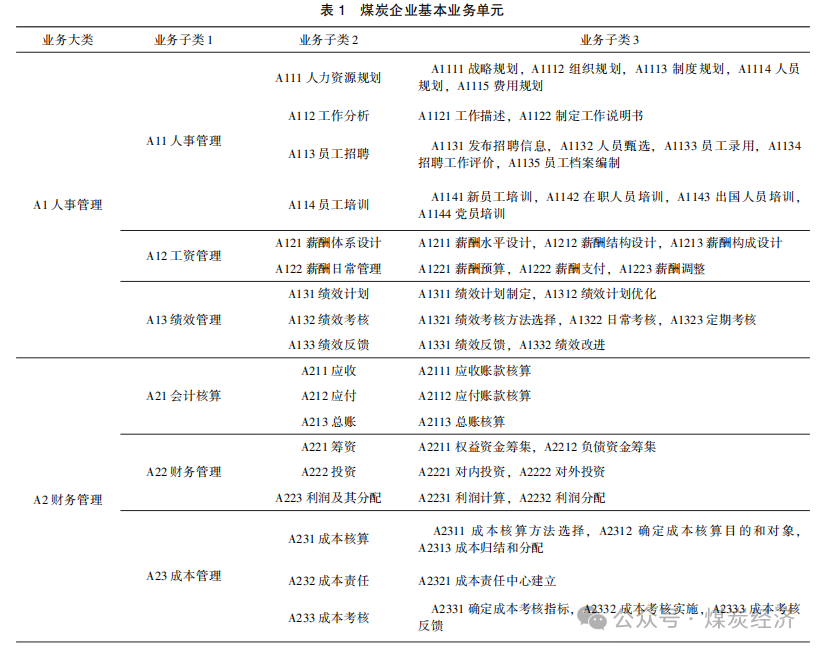
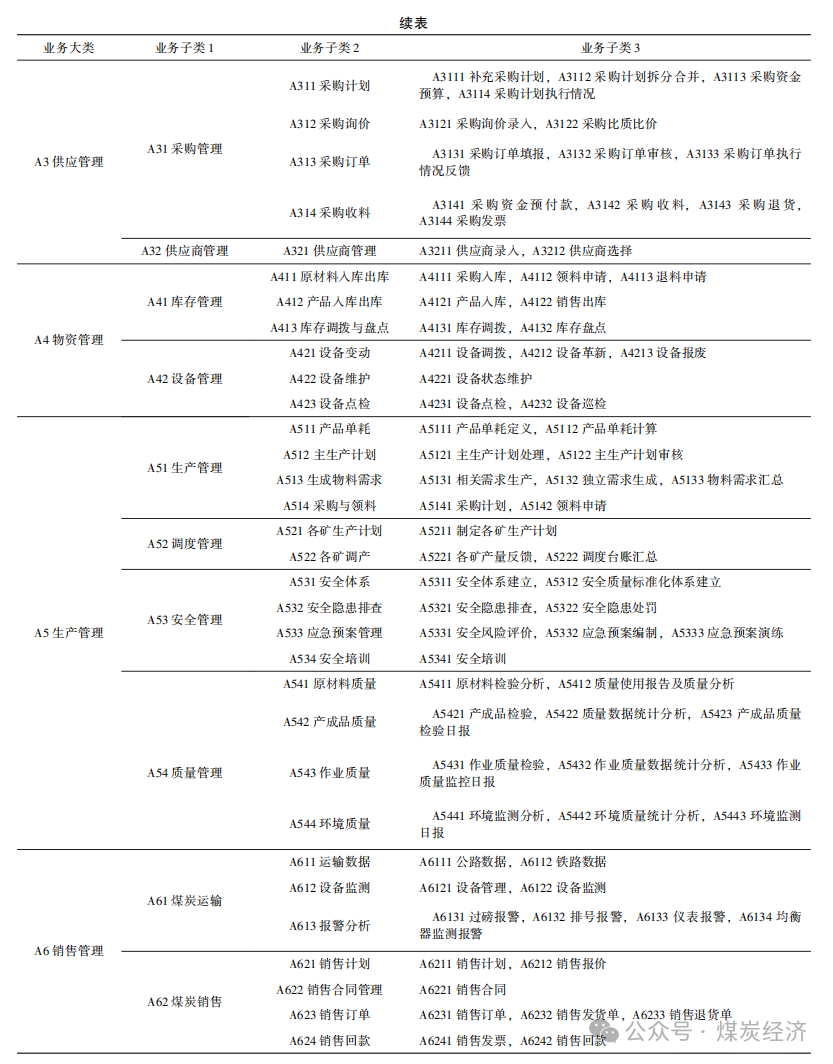
通过以上 5 个步骤 , 可将煤炭生产管理划分成 为基本的业务单元 。以此类推 , 运用 IDEF0 对煤炭 企业生产经营中的所有业务进行建模 , 可将煤炭企业生产经营业务划分成为最基本的业务单元 。表1为运用 IDEF0 划分的煤炭企业基本业务单元 , 包括6个业务大类 , 16个业务子类 1 , 50 个业务子类 2 , 120 个业务子类 3。
以上通过 IDEF0 建模方法 , 将煤炭企业业务划分成了最小的业务单元 , 即表 1中的业务子类 3 ,以此为依据 , 提取煤炭企业数据元。

由此 , 可根据表 1 所确定的煤炭企业最小业务单元 , 提取出每一个最小业务单元所对应的数据元。
主数据辨识指标分析
根据各个最小业务单元所提取的数据元 , 可确定出企业的疑似主数据元 , 即在最小业务单元中重复一次以上的数据元 。
根据主数据定义 , 主数据具有重要性、共享性和稳定性 3 方面的特性 , 因此从以下 3 方面分析主数据辨识指标。
1) 重要性 。
即该数据元在核心业务处理时的重要性 。重要性主要体现在核心业务中的重要性上, 比如生产管理、 安全管理、 财务管理等, 可用该数据元所在的最小核心业务单元中业务流程应用的频数来衡量, 可用 ω1 来表示。统计企业中流程应用的频数 , 得出其评分标准 , 具体得分记为 X , 按下式计算。

2) 共享性 。
即该数据元是否在多个业务单元 中存在 。共享性可用该数据元在最小业务单元中出现的频数来衡量 , 可用 ω2 来表示 。统计企业中各疑似主数据元在最小业务单元中出现的频数 , 得出其评分标准 , 具体得分记为 Y, 按下式计算。
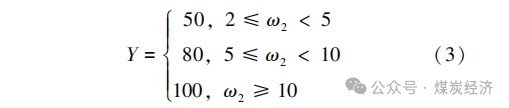
3) 稳定性 。
即该数据元在单位时间内所对应的数据变更频数 。如果数据变更频数高 , 说明数据稳定性差 ; 如果数据变更频率低 , 说明数据稳定性强 。数据元在单个最小业务单元中每月数据变更频数可用 ω3 来表示 。统计各疑似数据元的每月数据变更频率 , 得出其评分标准 , 具体得分记为 Z , 按下式计算。
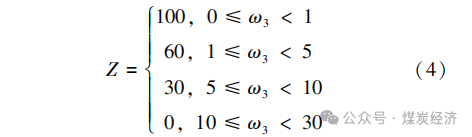
主数据辨识分析
基于上述对主数据辨识指标的分析 , 结合煤炭企业对主数据重要性 、共享性和稳定性的不同重视程度 , 在咨询煤炭企业数据管理专家的基础上 , 对 3 个指标进行权重估值 , 要求其权重相加为1,得出主数据指标权重的大概取值分别为重要性 40% , 共享性 40% , 稳定性 20% 。在实际中 , 该指标权重赋值可根据企业对各指标权重重视程度的不同来加以调 整 。 由此可得主数据辨识的最终得分公式如下。
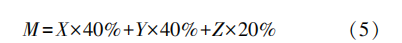
主数据辨识流程
结合主数据辨识公式 , 可总结出主数据辨识流程 , 如图 13 所示 。
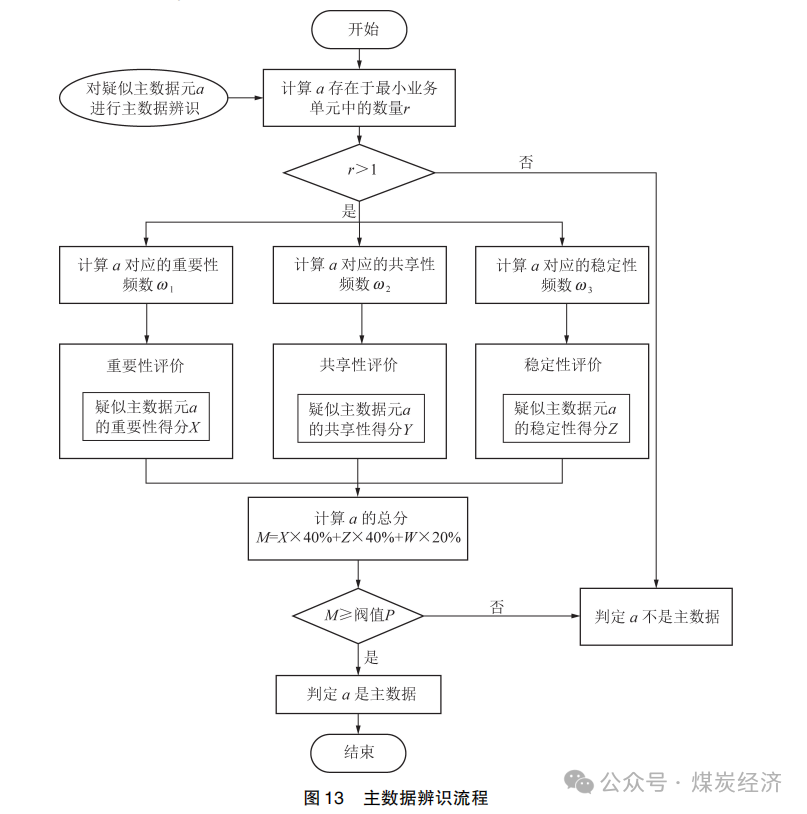
可分为以下几个步骤。
1) 计算 a 存在于最小业务单元的数量 r , 若r>1 , 则开始辨识 ; 若 r≤1,则 a 不是主数据。
2) 计算疑似主数据元 a 所对应的重要性频数 ω 1、共享性频数 ω2 和稳定性频数 ω3 。
3) 根据重要性频数ω 1,对疑似主数据元a的重要性进行评价 , 得出重要性得分X。根据共享性频数ω2 , 对疑似主数据元a的共享性进行评价 , 得出共享性得分Y。根据稳定性频数ω3 ,对疑似主数据元 a 的稳定性进行评价 , 得出稳定性得分Z。
4) 按照式(6)计算疑似主数据元 a 的总体得分。若 M ≥ 阈值 P , 则判定 a 是主数据 ; 若 M ≤ 阈值 P , 则判定 a 不是主数据。
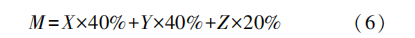
以上流程中 , 阈值 P 可由企业根据所有疑似主数据元的得分, 由大到小进行排序,以及企业管控的主数据多少来加以确定。
作者简介:刘婵( 1983— ),女,陕西西安人,副教授,博士,主要从事智能化煤矿数据治理、信息标准化等方面的教学与科研工作。E-mail:shirley9004@126. com

