


中国期刊全文数据库收录期刊
中国核心期刊(遴选)数据库收录期刊
中国学术期刊综合评价数据库统计源期刊
美国化学文摘(CA)数据库收录期刊
日本科学技术振兴机构(JST)数据库收录期刊

面向选煤生产 服务选煤行业
— 热点文章 —
本文通过研究面向选煤厂领域知识图谱的数据分类方法,探讨了如何利用先进的数据分类技术来构建和优化知识图谱,从而实现对选煤工艺数据的智能化管理与分析。文章系统介绍了数据分类方法在知识图谱构建中的应用,深度挖掘了其在选煤厂领域的实际应用场景和意义。通过本文的研究,为选煤厂数据处理和管理提供了新的思路和方法,对于推动选煤厂领域数据智能化建设具有积极的促进作用。
文章信息
01文章题目
面向选煤厂领域知识图谱的数据分类方法
02基金项目
无
03作者简介
赵 欣(1985—),男,黑龙江伊春人,工程师,从事选煤厂生产技术、智能化建设方面工作。
E−mail:xin1733@126.com
04作者单位
中煤华晋集团有限公司
主要内容
05文章摘要
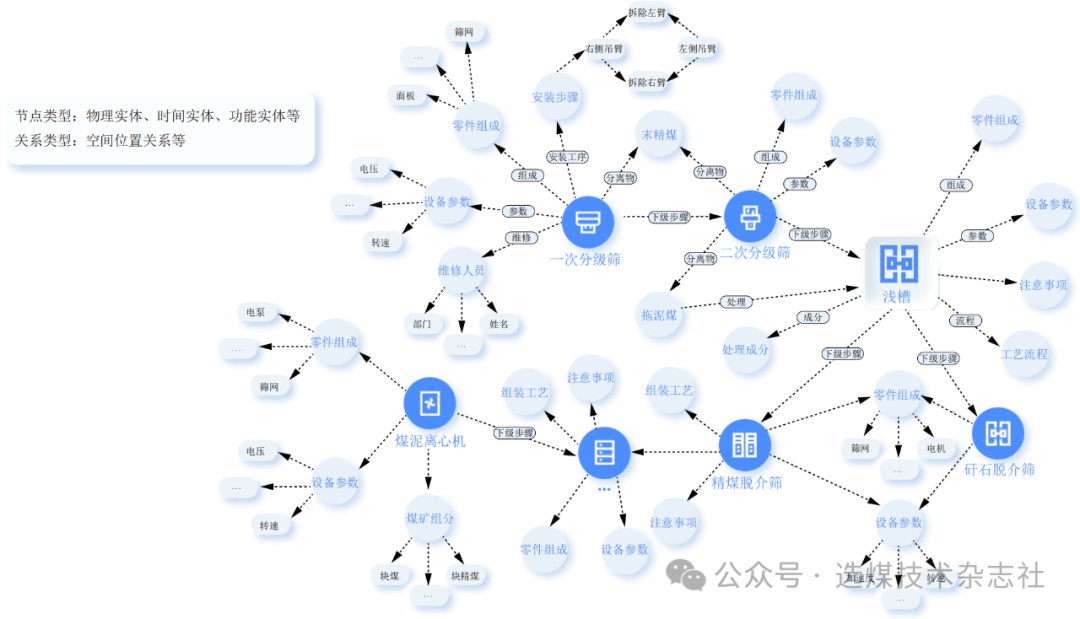
工业数据资源的开放共享是工业大数据产业发展的重要途径,选煤厂数据的自动分类有利于实现高效的数据管理。然而选煤厂数据纷繁复杂,数据之间存在交叉重叠和孤立无关联等问题,导致选煤厂数据缺乏标准化和规范化,制约了面向选煤厂智能化应用的发展。针对选煤厂结构化库表数据中标签数据少、数据交叉重叠等问题,提出一种基于知识图谱的选煤厂结构化库表数据自动分类算法。通过选煤厂领域的主题词列表构建了选煤厂领域知识图谱;以选煤厂领域知识图谱为基础,提出将KG-BERT分类模型用于非主题数据的扩展分类;基于TF-IDF的多主题权重判定模型,利用知识图谱的知识体系增强了文本分类的可控性和可解释性;结合选煤厂领域知识图谱、KG-BERT 分类模型以及基于TF-IDF的主题权重判定模型,提出用基于多模型融合的分类模型来实现选煤厂结构化库表数据自动分类。实验数据均来自选煤厂结构化库表数据全量目录,可验证算法的有效性。对比实验表明:KG-BERT分类模型采用了BERT 架构,具有一定的泛化能力,相较于CNN,RNN,LSTM 模型能较好应对无主题情况下的文本分类任务;从训练数据集上看,KE数据集在模型上表现更好;基于多模型融合的分类模型在选煤厂领域结构化库表数据分类较单一模型具有更好的有效性和适用性。基于多模型融合的分类模型自动分类效果良好,有助于提升选煤厂数据管理效率,进一步挖掘选煤厂数据资源的潜在价值。
06引用格式
ZHAO Xin, ZHANG Shusen. Coal preparation plant domain knowledge graph oriented data classification method[J]. Coal Preparation Technology,2024,52(2):73−79.
07文章引言
选煤厂数据纷繁复杂,数据之间交叉重叠或孤立无关联,导致选煤厂数据缺乏标准化和规范化。例如运维日志文件,对于由 PLC采集的数据,不同厂商传感系统数据的标准不统一,数据格式各异,日志文档的数据格式也与 IoT系统有较大差异。这些问题为选煤厂数据的高效管理带来了挑战。因此,如何实现选煤厂多源异构数据的自动分类,对指导业务场景的实际工作可产生较大效用,对借助大数据、人工智能技术实现选煤厂数据的有效管理具有重要意义。

扫码阅读全文


选煤技术
COAL PREPARATION TECHNOLOGY

>>关注我们<<

数字编辑:冯建楠
审 核:赵宏馨
版权说明:刊登所有稿件均按照国家版权局有关规定支付相应稿费,《选煤技术》享有稿件信息网络传播权。未经授权,不得匿名转载。本平台所使用的图片属于相关权利人所有,因客观原因,部分作品如存在使用不当情况,请相关权利人随时与编辑部联系。


