一个机器人一次性向所有机器人学习?全球34个实验室联合研究
机器人不能依赖于从互联网上抓取训练数据,而要从机器人数据中学习,这些数据通常由研究人员在实验室环境中为特定任务创建。如果没有丰富的数据,就无法让机器人在实验室外完成现实世界的任务。科学家希望从世界各地所有机器人共享的数据中受益,同时融入互联网数据赋予机器人推理能力,以此开发通用机器人大脑,驱动任何机器人。

来自世界各地的机器人分享数据,帮助开发通用机器人大脑
大语言模型可以回答问题、写代码、吟诗,图像生成系统可以创造洞穴壁画、当代艺术。那么,能擦桌子、叠衣服、做早餐的通用机器人在哪里?如果将许多机器人的经验汇集在一起,一个新的机器人是否可以一次性向所有机器人学习呢?2023年,谷歌和加州大学伯克利分校的实验室与北美、欧洲和亚洲的其他32个机器人实验室一起开展了RT-X项目,试图开发通用机器人大脑。这34个实验室的目标是汇集数据、资源和代码,使通用机器人成为现实,让单一深度神经网络控制不同类型的机器人。最近,加州大学伯克利分校副教授、谷歌研究科学家谢尔盖·莱文(Sergey Levine)等人撰文分享了这个全球项目的进展和成果。他设想也许未来机器人的新技能可以通过模型微调甚至是预训练模型来实现,就像在不训练ChatGPT的情况下让它讲一个故事一样,未来可以让机器人在蛋糕上写“生日快乐”,而不必告诉它如何使用裱花袋或手写文本是什么样的。
机器人把苹果放在罐头和橙子中间。(00:18)
创造一个通用机器人
生成式人工智能利用互联网上的大量数据训练大模型,但这些成果并不能轻易转移到机器人领域,因为机器人不能依赖于从互联网上抓取训练数据,互联网上也没有大量的机器人交互数据。
机器人需要从机器人数据中学习,而这些数据通常由研究人员在实验室环境中为特定任务缓慢而乏味地创建。尽管机器人学习算法取得了巨大进步,但如果没有丰富的数据,我们仍然无法让机器人在实验室之外完成现实世界的任务。
为此,科学家试图利用多种机器人的不同数据,来解决机器人的学习问题,制造通用机器人大脑。
“一个深度神经网络能否在来自足够多不同机器人的数据上训练,从而学会驱动具有不同外观、物理特性和能力的所有机器人?如果可行,这可能会为机器人的学习解锁大型数据集的力量。”莱文表示,RT-X数据集目前包含了22种机器人、近100万次试验,数据集中的机器人执行拾放物体、组装等各种行为,这是目前真实机器人动作的最大开源数据集,研究人员可训练机器人控制算法。
“就像一个人可以用同一个大脑开车或骑自行车一样,在RT-X数据集上训练的模型可以简单地从机器人自己的摄像头观察中识别出它所控制的机器人类型。”莱文举例,如果机器人的摄像头看到UR10工业臂,该模型将发送适合UR10的命令。
为了测试模型能力,参与RT-X项目的5个实验室,将他们独立开发的机器人最佳控制系统跟RT-X数据集训练出来的模型进行对比。结果显示,统一模型比每个实验室自己的最佳方法具有更好的性能,平均成功率提高了50%左右。
研究人员还发现,RT-X训练出来的模型可以利用其他机器人的不同经验来提高不同环境下的鲁棒性。即使在同一个实验室里,每次机器人尝试一项任务时,它都会发现自己处于略有不同的情况中,因此会借鉴其他机器人在其他情况下的经验。
创造一个会推理的机器人
复杂的语义推理很难单独从机器人数据中学习。虽然机器人数据可以提供一系列物理能力,但像“把苹果移到罐头和橙子之间”这类更复杂的任务,往往需要理解图像中物体间的语义关系、基本常识,以及和机器人物理能力没有直接关系的其他符号知识。
因此,研究人员在RT-X项目的机器人数据中加入了一个庞大数据源:互联网规模的图像和文本数据。他们使用现有的视觉语言模型,这个模型类似于ChatGPT或Bard等公众可用的模型,已精通需理解自然语言和图像之间联系的任务。结果发现,只要训练这个模型,让其对机器人指令(例如把香蕉放在盘子上)做出反应,就可以适应机器人控制。
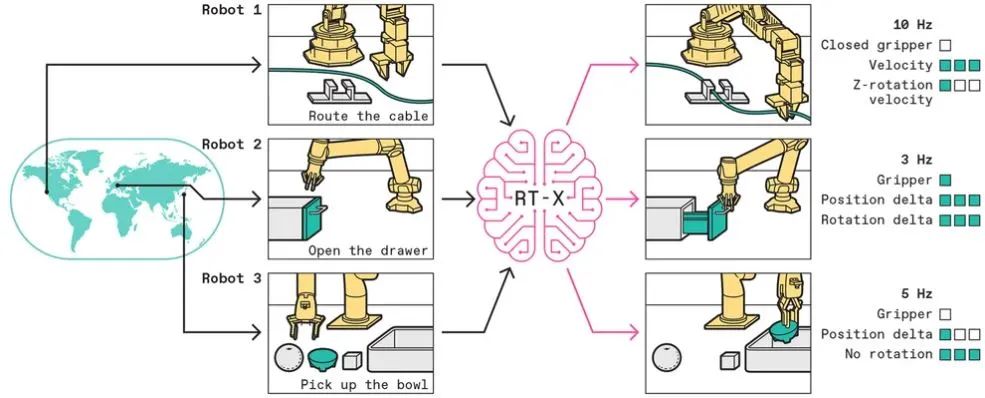
RT-X模型使用执行不同任务的特定机械臂的图像或文本描述,输出一系列离散动作,使任何机械臂都能完成这些任务。从世界各地的机器人实验室收集各种机器人完成各种任务的数据,构建开源数据集,可以让机器人变得通用为了评估互联网数据和多机器人数据的结合,研究人员用谷歌的移动机械臂对RT-X模型进行了严格泛化基准测试,机器人必须识别物体并成功地操纵物体,它还必须通过逻辑推理来响应复杂的文本命令,而运用逻辑推理就需要整合文本和图像信息,这是人类所擅长的本领。研究人员要求机器人执行训练数据中没有的任务,虽然这些任务对人类来说很简单,但对通用机器人而言是挑战。他们让谷歌机器人把苹果移到罐头和橙子之间,这涉及空间关系推理。在另一项任务中,谷歌机器人必须解决基本数学问题。这些挑战是为了测试机器人推理和得出结论的能力,其中,空间推理等推理能力来自视觉语言模型的网络数据训练,基于机器人行为的推理输出能力来自RT-X的数据训练。结果显示,包含多机器人RT-X数据的谷歌机器人,其任务泛化能力提高了三倍。这一结果表明,多机器人RT-X数据不仅有助于机器人获得各种物理技能,还有助于更好地将这些技能与视觉语言模型中的语义和符号知识联系起来。莱文认为,这些联系赋予了机器人常识,有朝一日这或使得机器人能够理解复杂而微妙的用户命令含义,比如机器人能理解“给我拿早餐”的命令,同时执行这个动作。这些进展还只是RT-X项目的第一步。“我们希望通过这第一步,一起创造机器人的未来:通用机器人大脑可以驱动任何机器人,从世界各地所有机器人共享的数据中受益。”莱文希望更多研究人员的数据可以贡献给RT-X数据库,但RT-X项目不仅仅是跨实验室共享数据,他希望RT-X发展成一个协作项目,以开发数据标准、可重复使用模型,以及新技术和算法。“就像大语言模型已经掌握了基于语言的广泛任务一样,未来我们可能会使用相同的大模型作为许多现实世界机器人任务的基础。也许机器人的新技能可以通过微调甚至是预训练模型来实现。”莱文说,就像在不训练ChatGPT的情况下让它讲一个故事一样,未来可以让机器人在蛋糕上写“生日快乐”,而不必告诉它如何使用裱花袋或手写文本是什么样的。当然,还需要对这些模型进行更多研究才能让机器人具备这种通用能力。莱文希望进一步推动单一神经网络控制多个机器人的前沿探索。这些进步可能包括添加来自生成环境的各种模拟数据、处理具有不同数量的手臂或手指的机器人、使用不同的传感器套件,甚至结合操作和运动行为。“RT-X为此类工作打开了大门,但最令人兴奋的技术发展仍在前方。”





